

Have you ever wondered how big apps like social media platforms, online stores, or banking apps stay fast even when millions of people use them at the same time? The secret often lies behind the scenes, in database clustering, replication & sharding, key techniques used to design scalable, high-performance database architectures.
When a database grows, a single server can struggle to keep up. Pages load slowly, data updates lag, and sometimes the system just crashes. That’s where database clustering, replication, and sharding come into play. Think of them as smart ways to organize and share the workload so your database doesn’t get overwhelmed.
In this guide, we’ll break down these concepts in simple, and practical insights anyone can understand.
What Is Database Scalability?
Database scalability refers to a system’s ability to handle increasing workloads without losing performance. This could mean more users, more stored data, or more requests per second.
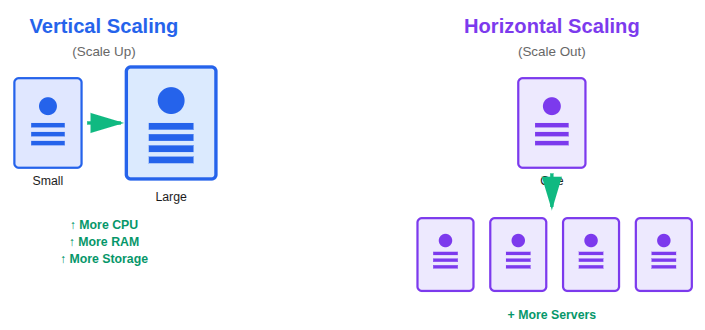
There are two main ways databases scale:
- Vertical scaling, which involves upgrading server resources
- Horizontal scaling, which involves adding more servers
Clustering, replication, and sharding are all horizontal scaling techniques designed to overcome the limits of a single database server.
Understanding Database Clustering
Database clustering connects multiple database servers into a single system that works together. These servers are aware of each other and coordinate to keep the database available.
If one node fails, another node continues serving requests. This makes clustering ideal for systems where uptime is critical.
Key points of database clustering
- Multiple servers act as one database: Several database servers work together and appear as a single system to users and applications.
- Automatic failover support: If one server stops working, another server takes over automatically without manual intervention.
- High availability and fault tolerance: The database remains accessible and stable even when hardware or software issues occur.

Types of Database Clustering
There are different clustering models depending on how data is handled:
- Active-active clustering: All database nodes are live and handle requests at the same time, helping distribute the workload evenly.
- Active-passive clustering: One database node actively serves requests while the others remain on standby, ready to take over if needed.
- Shared-nothing clustering: Each database node operates independently with its own storage and memory, reducing dependency and improving scalability.
The choice depends on performance needs and infrastructure complexity.

Benefits of Database Clustering
- Minimal downtime: The system continues running with little or no interruption even when a server issue occurs.
- Automatic failover: Database operations are quickly shifted to another server when the primary one becomes unavailable.
- Increased system reliability: The overall database setup becomes more stable and dependable under failures or high load.
Clustering is especially useful for mission-critical systems where outages are unacceptable.
How Database Replication Works
Database replication involves copying data from one database server to one or more additional servers.
The main server usually handles write operations, while replica servers handle read operations. Data changes are continuously synced to replicas.
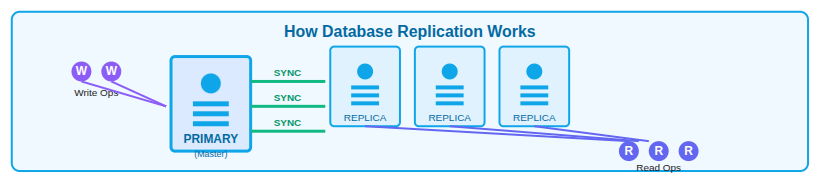
Core aspects of replication
- Primary and replica servers: One main database handles data changes while replica servers keep updated copies of that data.
- Data synchronization: Changes made on the primary database are continuously copied to replica databases to keep data consistent.
- Improved read performance: Read requests can be served by replica servers, reducing load on the primary database.
- Data redundancy: Multiple copies of the same data exist across servers, helping protect against data loss.
Types of Database Replication
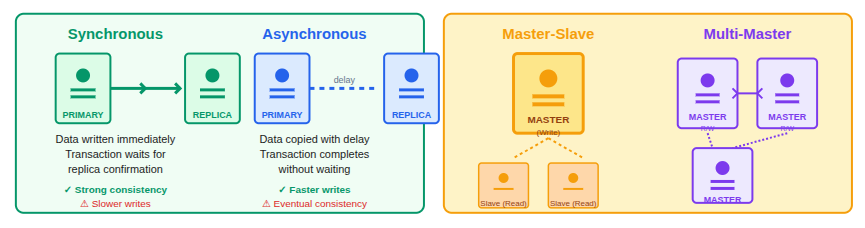
Replication can be configured in different ways:
- Synchronous replication, where data is written to replicas immediately
- Asynchronous replication, where data is copied with a slight delay
- Master-slave replication, with one write node
- Multi-master replication, with multiple write nodes
Each type balances performance and data consistency differently.
Benefits of Database Replication
- Faster read operations: Read requests are handled by replica servers, which reduces response time and improves performance.
- Backup and recovery options: Replicated databases provide up-to-date copies that can be used during failures or data restoration.
- Load distribution: Traffic is spread across multiple database servers, preventing any single server from becoming overloaded.
It is widely used in content-heavy and read-intensive applications.
What Is Database Sharding?
Database sharding splits a large database into smaller parts called shards. Each shard stores a subset of the data and runs on its own server.
Instead of one server managing all data, multiple servers manage different portions. This approach is highly effective for large-scale applications.
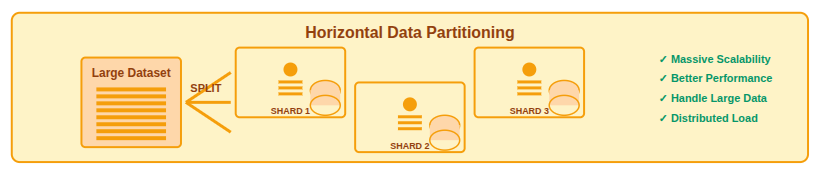
Key characteristics of sharding
- Horizontal data partitioning: Large datasets are split into smaller parts and stored across multiple servers based on defined rules.
- Independent database shards: Each shard operates as its own database, managing only a specific portion of the data.
- Improved write and read performance: Workloads are spread across shards, allowing the database to process requests more efficiently.
Benefits of Database Sharding
- Massive horizontal scalability: The system can grow by adding more servers instead of upgrading a single machine.
- Better performance under heavy load: Traffic is spread across multiple servers, preventing slowdowns during high usage.
- Efficient handling of large datasets: Large volumes of data are managed more effectively by distributing them across multiple databases
It allows databases to grow without relying on a single powerful server.
How Sharding Distributes Data
Data is distributed based on a shard key, such as user ID or geographic region.
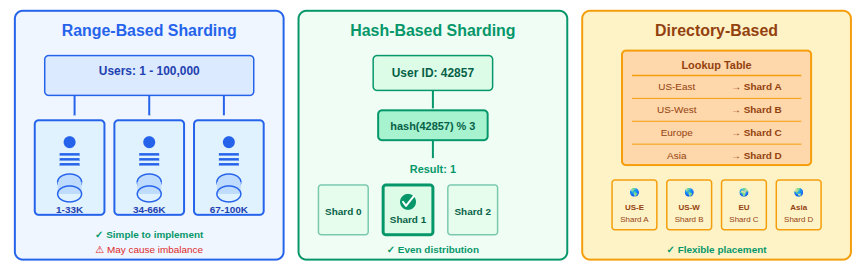
Common sharding methods include
- Range-based sharding: Data is divided into shards based on value ranges, such as numeric or alphabetical order.
- Hash-based sharding: A hash function is used to evenly distribute data across shards, reducing imbalance.
- Directory-based sharding: A lookup table is used to decide which shard stores specific data, allowing flexible placement.
Choosing the right shard key is critical for balanced data distribution and performance.
Clustering vs Replication vs Sharding
Each method serves a different purpose:
| Aspect | Database Clustering | Database Replication | Database Sharding |
| Primary goal | Ensure high availability and uptime | Improve read performance and data safety | Scale databases for very large data and traffic |
| How it works | Multiple servers work together as one database system | Data is copied from a primary server to one or more replicas | Data is split into smaller parts across multiple servers |
| Data distribution | Same data available across cluster nodes | Same data stored on primary and replicas | Different data stored on different shards |
| Main benefit | Automatic failover and fault tolerance | Redundancy and faster read operations | Horizontal scalability and performance |
| Write operations | Usually handled by one active node or coordinated nodes | Writes go to the primary server | Writes are distributed across shards |
| Read operations | Can be handled by multiple nodes | Mostly served by replica servers | Served by the shard holding the data |
| Scalability type | Improves availability more than scale | Improves read scalability | Improves both read and write scalability |
| Failure handling | Another node takes over automatically | Replicas can replace the primary if needed | Failure affects only the specific shard |
| Complexity level | Medium | Low to medium | High |
| Use case | Systems where downtime is unacceptable | Read-heavy applications | Very large, high-traffic applications |
| Data consistency | Strong consistency depending on setup | Depends on sync type (sync or async) | Must be handled carefully by the application |
| Ease of setup | Moderate | Easier to implement | More complex to design and maintain |
- Clustering improves availability
- Replication improves data redundancy and read scalability
- Sharding improves scalability for large datasets
They are not competing solutions but complementary techniques.

Why Applications Need These Techniques
Modern applications demand:
- High availability: The database remains accessible to users even when individual servers fail.
- Fast response times: Requests are processed quickly by distributing workload across multiple database servers.
- Data reliability: Data stays accurate and protected through redundancy and controlled synchronization.
- Scalability without downtime: The system can grow and handle more load without requiring service interruptions.
Without clustering, replication, or sharding, databases quickly become bottlenecks as applications grow.
Common Challenges and Limitations
Despite their benefits, these techniques introduce complexity.
Common challenges include
- Data consistency issues: Keeping data perfectly synchronized across multiple servers can be challenging, especially during updates.
- Complex maintenance: Managing clustered, replicated, or sharded databases requires more planning and operational effort.
- Monitoring and debugging difficulties: Tracking performance issues becomes harder when data and workload are spread across many servers.
- Application-level changes for sharding: Applications often need additional logic to decide which shard should handle each request.
Proper planning and testing are essential.
When and How to Use Each Approach
- Use clustering when high availability is required.
- Use replication when read traffic increases or redundancy is needed.
- Use sharding when data size and write traffic exceed single-server limits.
Many systems start with replication and later introduce clustering or sharding as needed.
Combining Clustering, Replication, and Sharding
Large-scale systems often combine all three techniques.
For example:
- Each shard may have replicas
- Replicas may run in a clustered setup
This layered approach provides performance, reliability, and scalability together.
Best Practices for Beginners
- Start with replication before sharding: Replication is easier to manage and should be implemented before moving to more complex sharding setups.
- Monitor performance regularly: Continuously tracking database metrics helps identify issues before they affect users.
- Plan scaling early: Designing the database with future growth in mind prevents major changes later.
- Test failover scenarios: Regular testing ensures the system can recover smoothly when a server fails.
You don’t need to do everything at once. Grow step by step.
Future of Database Scaling
As data continues to explode, these techniques will only become more important.
Cloud-native databases, managed services, and automation tools are making clustering, replication, and sharding easier than ever, even for small teams.
The future is all about smart scaling, not just bigger servers.
FAQs
1. What is the main purpose of database clustering?
Database clustering is mainly used to ensure high availability by allowing multiple servers to work together and handle failures without downtime.
2. How is database replication different from backups?
Replication continuously copies live data to other servers, while backups are periodic snapshots taken for recovery purposes.
3. When should a database be sharded?
Sharding should be considered when data size or write traffic grows beyond what a single database server can efficiently handle.
4. Can clustering, replication, and sharding be used together?
Yes, many large systems combine all three to achieve availability, scalability, and reliability at the same time.
5. Is database sharding complex to manage?
Yes, sharding adds complexity because applications must know how to route data to the correct shard, which requires careful planning and design.
Conclusion
Database clustering, replication, and sharding are no longer advanced concepts limited to large enterprises, they are essential techniques for building modern, scalable, and reliable applications. Each approach solves a specific problem: clustering ensures high availability, replication improves data safety and read performance, and sharding enables databases to grow beyond the limits of a single server.
Rather than choosing one over the others, successful systems often combine these techniques based on their needs and growth stage. The key is to understand when and why to use each method. By planning early, monitoring performance, and scaling step by step, teams can avoid bottlenecks and maintain smooth database operations as demand increases. In the long run, smart database scaling leads to better performance, higher uptime, and a more stable application experience.
Stop Wasting Time on Servers. Start Building Instead.
You didn’t start your project to babysit servers. Let ServerAvatar handle deployment, monitoring, and backups — so you can focus on growth.
Deploy WordPress, Laravel, N8N, and more in minutes. No DevOps required. No command line. No stress.
Trusted by 10,000+ developers and growing.